深度解析谷歌Genie 3:“一句话,创造一个世界”
想象一下,你只需对电脑说一句话:“一个雨后湿滑的赛博朋克城市,霓虹灯在水坑中闪烁”。几秒钟后,你不再是观看一段预先渲染的视频,而是亲自驾驶着飞行器,在这个为你而生的世界里自由穿梭。这不是科幻,这是谷歌DeepMind最新发布的Genie 3为我们揭示的未来序章。
在人工智能生成内容(AIGC)的浪潮中,我们已经见证了OpenAI的Sora、Runway和Pika等模型在文生视频领域的惊艳表现,它们能将文字描绘的想象转化为逼真的动态影像。然而,Genie 3的发布标志着一次根本性的范式转移。它不是另一个视频生成工具,而是一个“生成式交互环境”(Generative Interactive Environment),或者更准确地说,是一个“世界模型”(World Model)。其核心区别在于,它让用户从内容的“被动消费者”转变为世界的“主动参与者”,实现了从“观看”到“游玩”的惊人一跃。
Genie 3并非横空出世。它的诞生源于一个清晰且宏大的战略目标。其前身Genie 1和Genie 2已经为生成可供AI智能体(Agent)训练的环境奠定了基础。从一开始,Genie项目的最终使命就直指人工智能的“圣杯”——通用人工智能(Artificial General Intelligence, AGI)。谷歌DeepMind的科学家们在多个场合反复强调,世界模型是通往AGI之路的关键基石。
Genie 3的发布也揭示了顶级AI实验室之间战略路径的深刻分化。当一些公司致力于将AI打磨成增强人类创造力的强大工具时——例如Sora服务于电影制作人,Midjourney服务于艺术家——谷歌则在另一条赛道上全力冲刺:将AI构建为训练其他AI的“虚拟子宫”。这种差异并非简单的功能取舍,而是在通往高级人工智能道路上两种不同哲学和战略的选择。前者旨在赋能人类,而后者,即Genie 3所代表的路径,旨在创造能够自主学习和行动的机器智能。理解这一根本区别,是准确评估Genie 3真正价值和深远影响的关键。
您目前设备暂不支持播放
一、不只是“看”,更是“玩”:揭秘Genie 3的四大核心技术突破
Genie 3之所以能够实现从“视频”到“世界”的跨越,得益于其在多个核心技术上的重大突破。这些突破共同构建了一个前所未有的、可实时交互的虚拟现实。
突破一:实时交互性(Real-Time Interactivity)
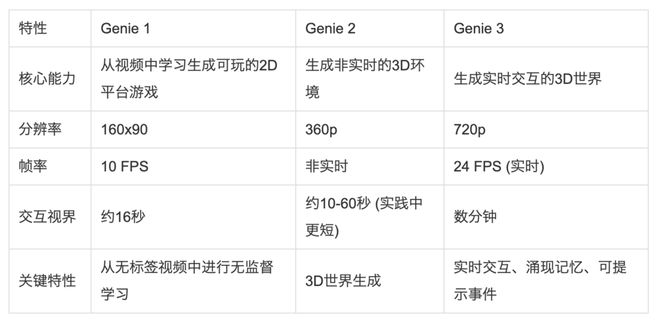
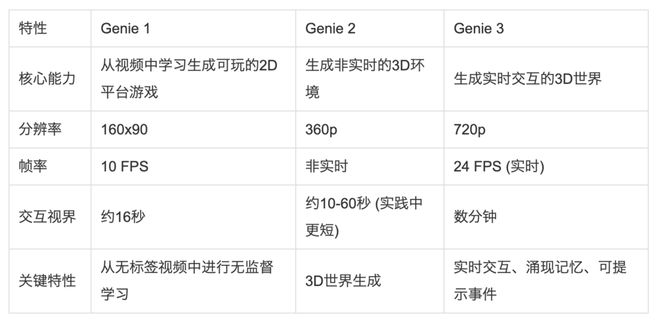
Genie 3最直观的飞跃在于其实时性。它能够以720p的分辨率和每秒24帧(24 FPS)的速率,实时生成并渲染整个世界。这与它的前身Genie 2形成了鲜明对比,后者生成每一帧都需要数秒的计算时间,无法提供流畅的交互体验。
打个比方,Genie 2的体验就像是观看别人玩游戏的录播,而Genie 3则让你亲自上手直播。你的每一个操作,无论是移动、跳跃还是转向,都会立刻得到世界的响应,而不是提交一个请求后,等待AI“画”出下一帧画面。这种即时反馈是学习的基石,无论是对于人类还是AI智能体。只有在一个能够对行为做出即时反应的环境中,智能体才能真正理解“因果关系”,学会如何通过行动影响世界。
突破二:持续数分钟的“交互视界” (An "Interaction Horizon" of Several Minutes)
Genie 3能够维持一个长达“数分钟”的、连贯且可交互的会话,这被称为“交互视界”(Interaction Horizon),这个持续性决定了其交互的深度。相比之下,Genie 2的交互视界理论上限虽有60秒,但在实践中,往往在10到20秒后,生成的世界就会开始“退相干”(decohere),出现逻辑混乱或视觉崩坏的“幻觉”现象。
交互时长的显著延长,意味着Genie 3可以支持更复杂的、需要多个步骤才能完成的任务模拟。这对于训练智能体进行“长远规划”(long-horizon planning)至关重要。对于人类用户而言,这意味着体验从一个转瞬即逝的技术演示,升级为了一个可以真正进行探索的“微型世界”。
突破三:涌现的视觉记忆 (Emergent Visual Memory)
这是Genie 3最令人惊叹的特性。在它生成的世界里,物体和环境的变化具有了一致性,即使在你视线离开后,这些变化依然存在。谷歌官方演示中最经典的例子是:用户在一个虚拟房间的墙上用滚筒刷涂上蓝色油漆,然后转身探索别处,当再次回头时,墙上的油漆痕迹依然清晰可见。
更关键的是,DeepMind的科学家强调,这种视觉记忆和世界一致性是一种“涌现”(emergent)的能力,并非通过硬编码规则明确编程实现的。可以将其理解为,一个极其强大的神经网络在学习了海量数据后,自发地领悟到了“物体恒存性”这一物理世界的基本规则。
这个特性意义非凡。之前的模型更像是条件反射式的图像生成器,而Genie 3则开始构建一个内在的、连贯的“世界模型”。一个能够理解“物体在我看不见时依然存在”的AI,离拥有真正的世界观又近了一步。
突破四:可提示的世界事件(Promptable World Events)
Genie 3不仅允许用户在世界中行动,还赋予了用户动态改变世界的能力。通过输入新的文本提示,用户可以实时地为当前环境注入新的元素或事件,比如在滑雪场景中凭空加入一群奔跑的鹿,或是在平静的湖面上瞬间召唤一场风暴。
这种能力赋予了用户“导演”或“上帝”般的权力。你不再仅仅是世界中的演员,还能在不中断体验的情况下,实时修改剧本和场景。对于AI训练而言,这意味着研究人员可以动态地向模拟环境中注入各种“意外”和“假设”情景(即“反事实”),从而在安全可控的环境下,测试智能体应对突发状况的鲁棒性和适应性,这是静态训练数据无法比拟的优势。
您目前设备暂不支持播放
下表对比了Genie系列模型的能力演进:
Genie系列模型能力演进对比表
二、AI的“头号玩家”训练场:Genie 3的真实使命与商业蓝图
尽管Genie 3在游戏、教育等领域展现了诱人的前景,但其最核心、最根本的使命,是成为训练下一代AI智能体的终极“试炼场”。
主要使命:AGI的熔炉(The AGI Crucible)
Genie 3最重要的应用是训练AI智能体,特别是“具身智能体”(Embodied Agents),如机器人和自动驾驶汽车。世界模型解决了机器人学和AGI研究中的一个核心瓶颈:对海量、多样化、安全且低成本的训练数据的渴求。在现实世界中训练一个仓库机器人或自动驾驶汽车,过程缓慢、成本高昂且充满危险。但在Genie 3生成的世界里,可以模拟数百万种驾驶情景或操作任务,包括那些在现实中极难遇到的“黑天鹅”事件,从而极大地提升智能体的鲁棒性和可靠性。谷歌已经将其SIMA(可扩展、可指导的多世界智能体)项目与Genie 3结合进行训练,这表明该应用已从理论走向实践。
这背后反映了AI发展理念的一次深刻转变:从“数据驱动的学习”迈向“经验驱动的智能”。传统的大型语言模型(LLM)通过学习互联网上的海量文本和图片数据,成为知识渊博的“学霸”,精通模式识别,但它们对物理世界的因果关系缺乏直观理解。而世界模型提供了一个动态的“沙盒”,智能体可以在其中采取行动、观察后果、形成反馈闭环 。通过这种虚拟的“亲身经历”,AI不再是死记硬背物理定律,而是像人类婴儿一样,通过与环境的互动,逐步建立起对物理世界的直观认知。这种从“书本知识”到“实践真知”的转变,是AI从模仿智能走向理解世界的关键一步。
应用二:游戏产业的双刃剑
Genie 3的发布在游戏行业描绘的前景无疑是颠覆性的:理论上,它可以将游戏场景的创建时间从数月缩短到几分钟,极大地降低开发成本。这有望实现游戏开发的“民主化”,让小型独立工作室甚至个人开发者,也能拥有创造宏大世界的能力。
然而,理想与现实之间是有鸿沟的。一些提前体验Genie 3的游戏研究者和开发者指出,作为一款“游戏引擎”,它目前存在明显短板。例如,它生成的游戏世界普遍缺乏良好的“游戏手感”(Game Feel),时常出现诡异的图形错误,最重要的是,通过提示词进行控制的方式既不精确也不可预测,远无法与Unreal或Unity等成熟引擎的精细化编辑能力相比。所以,在现阶段,Genie 3更适合作为激发创意的“构思工具”或快速验证想法的“原型工具”,而非用于商业项目的生产工具。
尽管如此,我们不能忽视驱动这一技术发展的强大经济动力。3A级游戏的开发成本正面临一场“成本危机”,动辄数亿美元的投入和数年的开发周期让许多工作室不堪重负。Genie 3所代表的技术方向,恰恰为解决这一核心经济问题提供了可能的答案。因此,即使它今天尚不完美,其未来的发展和最终被行业采纳,似乎已是一种不可逆转的趋势。
应用三:教育与模拟的未来
Genie 3的潜力同样延伸至教育领域。它能够创造出高度互动的沉浸式学习环境。想象一下,历史系学生不再是阅读枯燥的文本,而是可以亲身“走进”AI生成的古罗马城邦,与虚拟市民互动;医学院学生可以在模拟的急诊室中,反复练习应对各种突发状况,而无需承担任何真实风险。这种技术与更广泛的教育科技趋势不谋而合,即利用生成式AI和模拟技术,提供个性化的、实践性的学习体验,弥补传统课堂教学的不足。
您目前设备暂不支持播放
三、神仙打架:Genie 3与Sora、Runway的终极对决
对于普通用户来说,Genie 3、Sora、Runway等模型似乎都在做“AI生成视频”这件事。但深入剖析其核心技术和设计理念,会发现它们分属不同的物种。
核心区别:世界模型vs.视频模型
最根本的区别在于:Genie 3是一个用于模拟交互过程的世界模型,而Sora、Runway和Pika是用于生成最终结果的视频模型。
一个恰当的比喻是:Sora是一位技艺高超的画家,他能根据你的描述,为你创作一幅描绘宏大战争场面的、令人惊叹的油画。而Genie 3则是一个兵棋推演沙盘,它让你亲自指挥沙盘中的军队进行战斗。前者用于欣赏,后者用于操作。
下表对当前主流的生成式视频/世界模型进行了全方位对比: