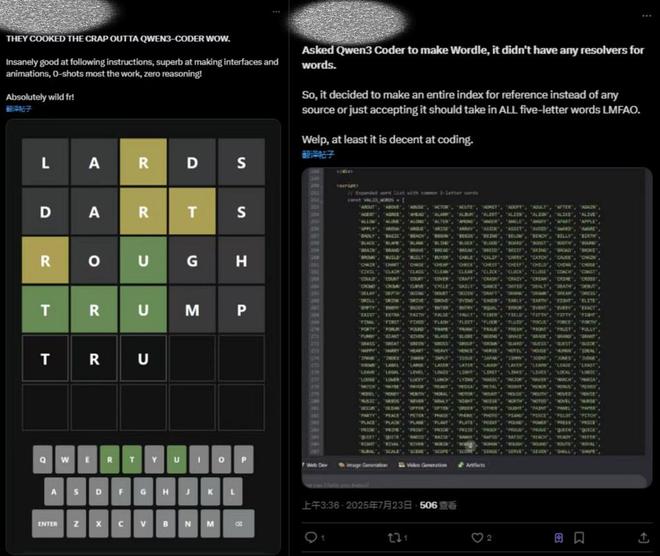
8999元!荣耀Magic V5发布,但这个AI杀招国内没有
智能手机AI大战,谁都希望是站在前面的那一个。荣耀也不例外,MagicOS 9.0带来了迭代后的30亿参数端侧大语言模型Nano ROM,比上一代的70亿参数大语言模型,ROM占用减少1.8GB、RAM占用减少1.6GB,加载速度提升77%。
最新发布的Magic V5上,AI智能体又一次进化,支持8种一语AI功能,想要手机干什么,动动嘴巴就行。
之所以要说荣耀的端侧平台级大语言模型,因为这是完全在机内靠本地算力的大语言模型。毕竟,受限于手机性能和存储/内存,多数AI功能的计算都必须联网完成,来确保AI的稳定性和最终效果,端云协同是目前AI手机最主流的方案,没了网络,AI“缺胳膊少腿”还真不是开玩笑的。荣耀实现了全球首个端侧语音大模型的部署,也算是重大突破——可惜的是,这一功能将在海外市场首发,因此荣耀这次发布会并没有提到相关的能力,但不妨碍我们去讨论端侧语音大模型的未来。
没网也能用AI,荣耀在玩一种很新的东西
实际上,如今的AI手机,里面都配备了多个大大小小的端侧模型。
以荣耀为例,其自研的“魔法大模型”家族里,包含了图像大模型、大语言模型、多模态模型和语音大模型。不同的大模型有对应的专项能力,也具有多种参数规模,用于支持不同系列的智能终端。就像荣耀的“大王影像”,也是通过大模型来优化图片的,OPPO也在超远焦段运用了AI大模型来提升数码变焦的图片质量。
但其中,大语言模型依赖庞大的参数规模,在手机上的端侧部署,模型精度和生成速度难以兼顾,一般会采用端云协同的方式在手机上部署,OPPO的AndesGPT、华为的盘古大模型、小米第二代大语言模型MiLM2等主流厂商的大语言模型,都采用了端云协同的方式,保证精度、响应、安全性。

(图片来自荣耀)
不同于大语言模型,语音大模型的参数规模远低于大语言模型,一般来说,大语言模型的参数在千亿级别,厉害一点的有万亿参数,而语音模型的参数量往往只有百万和千万级,体积和目前主流的手机App相当。
语音大模型和大语言模型虽然都涉及自然语言处理,但本质上是两类聚焦不同任务的AI模型,前者的核心价值在于处理语音信号和文本转换,以及优化语音交互的流畅性。
从应用场景上,语音大模型和大语言模型属于协作关系,前者分析用户的语音信号,转换为文字之后交给大语言模型理解并生成文字回馈,再通过语音大模型转为语音反馈给用户,这就是完整的“语音交互流程”。也就是说,如果手机没有集成大参数的端侧大模型,即便有端侧语音大模型,也很难做到理想的离线语音交互、智能实时翻译功能。
(图片来自雷科技摄制)
业内做离线端侧AI语音交互和离线实时本地翻译的手机品牌,目前基本上只有荣耀一家,结合荣耀自家的YOYO智能体,甚至能够支持离线状态下的自动执行,要不然也不拿“全球首个语音大模型端侧部署”来宣传。
离线AI交互是好主意,但不一定是好方向?
前面也提到,手机厂商为了平衡AI大模型的计算功耗、安全性和生成效果,大多数都会采用端侧小模型+云端大模型协同工作的方案。这种方案对手机运算压力小,也可以借助云端计算,让大模型提供更精确的生成结果。
只是很多人都没有想到无网络等极端环境下使用AI功能,雷科技试过在户外评测手机AI助手时,因为没有连接网络,手机的AI助手除了只会回应“请连接网络”外,什么都干不了。
这么看,荣耀让机圈看到了AI手机步入离线运算时代的希望,在一些没有网络或信号不佳的极端环境下,手机的AI功能也不至于“罢工”。另外,设备端大模型还有两大优势就是安全和响应快。
我还是要先泼一盆冷水,从科技平权的角度来看,完全离线运行的AI功能,短期内都不太可能在低端的机器上见到。本地运算高度依赖硬件,智能手机的性能参差不齐,适配难度相当高,过分压缩大模型规模也会导致生成精度严重损失,硬上语音大模型意义并不大。

(图片来自荣耀)
这也是为什么荣耀选择率先在配备高通骁龙8至尊版芯片的Magic V5上首发,如果在一些次旗舰芯片甚至是中低端芯片上适配大语言模型,它很可能理解不到各个地方的口音、模糊音、连读等刁钻的特殊语言,导致语音大模型发挥不出作用,厂商好心设计的功能变成了“痛点”。
雷科技曾经尝试过将DeepSeek 1.5B(15亿参数)的本地大模型下载到一台配备高通骁龙8至尊版芯片+16GB运行内存的手机上运行,结果就是它的表现还行,AI推理和生成速度比较不错,甚至不比一些笔记本电脑弱。
换个角度看,高通骁龙8至尊版+16GB这种配置的手机,基本上都是旗舰级别的产品,或者是主打高性能的中高端手机,才能获得一个相对不错的AI推理和生成体验。低端手机的AI算力目前几乎为0,所以绝大部分AI功能只能在云端处理,没有网络基本“报废”。
这还没算上大模型的规模和质量,比如15亿参数的DeepSeek在手机里也就只能说“能跑起来”,但生成出来的答案只能说难堪大用。不排除手机厂商通过一系列优化和压缩后的端侧大语言模型会有更好表现的可能,只能说再好也有限。
在手机性能这种刚性约束之下,完全本地计算的端侧大语言模型和语音模型会面临功耗与精度的“两难抉择”,一个理解能力有限,另一个就是,面对多变的使用环境(安静房间、嘈杂户外、远距离对话等),云端大模型可以靠大量数据进行约束提高生成精度,但这种高度压缩之后的端侧大模型能做到什么效果,这还真的不好说。